FITS_commentary_card_image := COMMENT_keyword
[ascii_text_char...] | HISTORY_keyword
[ascii_text_char...] | BLANKFIELD_keyword
[ascii_text_char...] | keyword_field anychar_but_equal
[ascii_text_char...] | keyword_field `=' anychar_but_space
[ascii_text_char...] {Constraint: The total number of
characters in a FITS_commentary_card_image must be exactly
equal to 80.}
FITS_value_card_image := keyword_field value_indicator
[space...] [value] [space...] [comment] {Constraint:
The total number of characters in a FITS_value_card_image must
be exactly equal to 80.} {Comment: if the value field is
not present, the value of the FITS keyword is not
defined.}
keyword_field := [keyword_char...] [space...]
{Constraint: The total number of characters in the
keyword_field must be exactly equal to 8.}
keyword_char := `A'-`Z' | `0'-`9' | `_' | `-'
COMMENT_keyword := `C' `O' `M' `M' `E' `N' `T' space
HISTORY_keyword := `H' `I' `S' `T' `O' `R' `Y' space
BLANKFIELD_keyword := space space space space space
space space space
character_string_value := begin_quote
[string_text_char...] end_quote {Constraint: The
begin_quote and end_quote are not part of the character string
value but only serve as delimiters. Leading spaces are
significant; trailing spaces are not.}
begin_quote := quote
end_quote := quote {Constraint: The ending quote
must not be immediately followed by a second quote.}
quote := \0x27
string_text_char := ascii_text_char {Constraint: A
string_text_char is identical to an ascii_text_char except for
the quote char; a quote char is represented by two successive
quote chars.}
logical_value := `T' | `F'
integer_value := [sign] digit [digit...] {Comment:
Such an integer value is interpreted as a signed decimal
number. It may contain leading zeros.}
sign := `-' | `+'
digit := `0'-`9'
floating_value := decimal_number [exponent]
decimal_number := [sign] [integer_part] [`.'
[fraction_part]] {Constraint: At least one of the
integer_part and fraction_part must be present.}
(This Appendix is not part of the NOST
FITS Standard but is included for informational
purposes only.) In the paper describing the binary table extension, type
name 'BINTABLE' (Cotton et al. 1995),
the authors present three conventions: one for variable length
arrays, one for multidimensional arrays and one for substring
arrays. These conventions, discussed in appendixes to the
proposal, are not part of the formal BINTABLE rules adopted by
the IAUFWG but are expected to enjoy wide acceptance. The
draft text for those appendixes, available on-line in the
directory http://www.cv.nrao.edu/fits/documents/standards/,
is reproduced here nearly verbatim; the only changes are those
required for stylistic consistency with the rest of this
document.
B.1 ``Variable length array''
facility
One of the most attractive features of binary tables is
that any field of the table can be an array. In the standard
case this is a fixed size array, i.e., a fixed amount of
storage is allocated in each record for the array data -
whether it is used or not. This is fine so long as the arrays
are small or a fixed amount of array data will be stored in
each record, but if the stored array length varies for
different records, it is necessary to impose a fixed upper
limit on the size of the array that can be stored. If this
upper limit is made too large excessive wasted space can
result and the binary table mechanism becomes seriously
inefficient. If the limit is set too low then it may become
impossible to store certain types of data in the table.
The "variable length array'' construct presented here was
devised to deal with this problem. Variable length arrays are
implemented in such a way that, even if a table contains such
arrays, a simple reader program which does not understand
variable length arrays will still be able to read the main
table (in other words a table containing variable length
arrays conforms to the basic binary table standard). The
implementation chosen is such that the records in the main
table remain fixed in size even if the table contains a
variable length array field, allowing efficient random access
to the main table.
Variable length arrays are logically equivalent to regular
static arrays, the only differences being 1) the length of the
stored array can differ for different records, and 2) the
array data is not stored directly in the table records. Since
a field of any datatype can be a static array, a field of any
datatype can also be a variable length array (excluding
type P, the variable length array descriptor itself,
which is not a datatype so much as a storage class specifier).
Conventions such as TDIMn (see
Appendix .4)
apply equally to both variable length and static arrays.
A variable length array is declared in the table header
with a special field datatype specifier of the form
where the "P'' indicates the amount of space occupied
by the array descriptor in the data
record (64 bits), the element count r should be 0, 1, or
absent, t is a character denoting the datatype of the array
data (L, X, B, I, J, etc., but not P), and is a quantity guaranteed to be
equal to or greater than the maximum number of elements of
type t actually stored in a table record. There is no built-in
upper limit on the size of a stored array; merely reflects the size of
the largest array actually stored in the table, and is
provided to avoid the need to preview the table when, for
example, reading a table containing variable length elements
into a database that supports only fixed size arrays. There
may be additional characters in the TFORMn keyword following the
.
For example,
indicates that field 8 of the table is a variable
length array of type byte, with a maximum stored array length
not to exceed 1800 array elements (bytes in this case).
The data for the variable length arrays in a table is not
stored in the actual data records; it is stored in a special
data area, the heap, following the last
fixed size data record. What is stored in the data record is
an array descriptor. This consists of two 32-bit
integer values: the number of elements (array length) of the
stored array, followed by the zero-indexed byte offset of the
first element of the array, measured from the start of the
heap area. Storage for the array is contiguous. The array
descriptor for field N as it would appear embedded in a
data record is illustrated symbolically below:
[field N-1] [(nelem,offset)] [field
N+1]
If the stored array length is zero there is no array data,
and the offset value is undefined (it
should be set to zero). The storage referenced by an array
descriptor must lie entirely within the heap area; negative
offsets are not permitted.
A binary table containing variable length arrays consists
of three principal segments, as follows:
[table_header] [record_storage_area] [heap_area]
The table header consists of one or more 2880-byte
FITS logical records with the last record indicated
by the keyword END somewhere in the
record. The record storage area begins with the next 2880-byte
logical record following the last header record and is bytes in length. The zero indexed byte offset of the heap measured
from the start of the record storage area is given by the
THEAP keyword in the header. If this
keyword is missing the heap is assumed to begin with the byte
immediately following the last data record, otherwise there
may be a gap between the last stored record and the start of
the heap. If there is no gap the value of the heap offset is . The total length in bytes of the heap area
following the last stored record (gap plus heap) is given by
the PCOUNT keyword in the table header.
For example, suppose we have a table containing 5 rows each
168 byte records, with a heap area 2880 bytes long, beginning
at an offset of 2880, thereby aligning the record storage and
heap areas on FITS record boundaries (this alignment
is not necessarily recommended but is useful for our example).
The data portion of the table consists of 2 2880-byte
FITS records, 840 bytes of which are used by the 5
table records, hence PCOUNT is , or 4920 bytes; this is
expressed in the table header as:
NAXIS1 = 168 / Width of table row in bytes
NAXIS2 = 5 / Number of rows in table
PCOUNT = 4920 / Random parameter count
...
THEAP = 2880 / Byte offset of heap area
The values of TSCALn and TZEROn
for variable length array column
entries are to be applied to the values in the data array in
the heap area, not the values of the array descriptor. These
keywords can be used to scale data values in either static or
variable length arrays.
While the above description is sufficient to define the
required features of the variable length array implementation,
some hints regarding usage of the variable length array
facility may also be useful.
Programs which read binary tables should take care to not
assume more about the physical layout of the table than is
required by the specification. For example, there are no
requirements on the alignment of data within the heap. If
efficient runtime access is a concern one may want to design
the table so that data arrays are aligned to the size of an
array element. In another case one might want to minimize
storage and forgo any efforts at alignment (by careful design
it is often possible to achieve both goals). Variable array
data may be stored in the heap in any order, i.e., the data
for record N+1 is not necessarily stored at a larger
offset than that for record N. There may be gaps in the
heap where no data is stored. Pointer aliasing is permitted,
i.e., the array descriptors for two or more arrays may point
to the same storage location (this could be used to save
storage if two or more arrays are identical).
Byte arrays are a special case because they can be used to
store a "typeless'' data sequence. Since FITS is a
machine-independent storage format, some form of
machine-specific data conversion (byte swapping, floating
point format conversion) is implied when accessing stored data
with types such as integer and floating, but byte arrays are
copied to and from external storage without any form of
conversion.
An important feature of variable length arrays is that it
is possible that the stored array length may be zero. This
makes it possible to have a column of the table for which,
typically, no data is present in each stored record. When data
is present the stored array can be as large as necessary. This
can be useful when storing complex objects as records in a
table.
Accessing a binary table stored on a random access storage
medium is straightforward. Since the data records in the main
table are fixed in size they may be randomly accessed given
the record number, by computing the offset. Once the record
has been read in, any variable length array data may be
directly accessed using the element count and offset given by
the array descriptor stored in the data record.
Reading a binary table stored on a sequential access
storage medium requires that a table of array descriptors be built up as the main table records are
read in. Once all the table records have been read, the array
descriptors are sorted by the offset of the array data in the
heap. As the heap data is read, arrays
are extracted sequentially from the heap and stored in the
affected records using the back pointers to the record and
field from the table of array descriptors. Since array
aliasing is permitted, it may be necessary to store a given
array in more than one field or record.
Variable length arrays are more
complicated than regular static arrays
and imply an extra data access per array to fetch all the data
for a record. For this reason, it is recommended that regular
static arrays be used instead of variable length arrays unless
efficiency or other considerations require the use of a
variable array.
This facility is still undergoing trials and is not part of
the basic binary table definition.
B.2 ``Multidimensional array''
convention
It is anticipated that binary tables will need to contain
data structures more complex that those describable by the
basic notation. Examples of these are
multidimensional arrays and nonrectangular data structures.
Suitable conventions may be defined to pass these structures
using some combination of keyword/value pairs and table
entries to pass the parameters of these structures.
One case, multidimensional arrays, is so common that it is
prudent to describe a simple convention. The "Multidimensional
array'' convention consists of the following: any column with
a dimensionality of 2 or larger will have an associated
character keyword TDIMn
='(l,m,n...)' where l, m,
n, ...are the dimensions of the array. The data is
ordered such that the array index of the first dimension given
(l) is the most rapidly varying and that of the last
dimension given is the least rapidly varying. The size implied
by the TDIMn keyword will equal the element count specified in
the TFORMn keyword. The adherence to this convention will be
indicated by the presence of a TDIMn keyword in the form
described above.
A character string is represented in
a binary table by a one-dimensional character array, as
described under "Character'' in the list of datatypes in
Sect. 8.3.3
("Main Data Table''). For example, a Fortran 77
CHARACTER*20 variable could be represented in a binary table
as a character array declared as
TFORMn='20A'. Arrays of character strings, i.e.,
multidimensional character arrays, may be represented using
the TDIMn notation. For example, if
TFORMn='60A' and TDIMn = '(5,4,3)',
then the entry consists of a array of strings of 5 characters each. (Variable
length character strings are allowed by the convention
described in Appendix .5.
One dimensional arrays of strings should use the convention in
Appendix .5
rather than the "Multidimensional Array'' convention.)
This convention is optional and will not preclude other
conventions. This convention is not part of the binary table
definition.
B.3 ``Substring array''
convention
This appendix
describes a layered convention for specifying that a character
array field (TFORMn = 'rA') consists of
an array of either fixed-length or variable-length substrings
within the field. This convention utilizes the option
described in the basic binary table definition to have
additional characters following the datatype code character in
the TFORMn value field. The full form for the value of TFORMn
within this convention is
'rA:SSTRw/nnn'
and a simpler form that may be used for fixed-length
substrings only is
'rAw'
where
r is an integer giving the total length
including any delimiters (in characters) of the field, A
signifies that this is a character array field, :
indicates that a convention indicator follows, SSTR
indicates the use of the "Substring Array'' convention,
w is an integer r giving the (maximum) number of characters in an
individual substring (not including the delimiter), and
/nnn if present, indicates that the substrings have
variable-length and are delimited by an ASCII text character
with decimal value nnn in the range 032 to 126 decimal,
inclusive. This character is referred to as the delimiter
character. The delimiter character for the last substring
will be an ASCII NUL.
To illustrate this usage:
'40A:SSTR8' signifies that the
field is 40 characters wide and consists of an array of 5
8-character fixed-length substrings. This could also be
expressed using the simpler form as '40A8',
'100A:SSTR8/032' signifies that the field is
100 characters wide and consists of an array of
variable-length substrings where each substring has a
maximum length of 8 characters and, except for the last
substring, is terminated by an ASCII SPACE (decimal 32)
character.
Note that simple FITS readers that do not
understand this substring convention can ignore the TFORM
characters following the rA and can interpret the field simply
as a single long string as described in the basic binary table
definition.
The following rules complete the full definition of this
convention:
1.
In the case of fixed-length substrings, if r is not an
integer multiple of w then the remaining odd characters are
undefined and should be ignored. For example if TFORMn
='14A:SSTR3', then the field contains 4 3-character
substrings followed by 2 undefined characters;
2.
Fixed-length substrings must always be padded with
blanks if they do not otherwise fill the fixed-length
subfield. The ASCII NUL character must not be used to
terminate a fixed-length substring field;
3.
The character following the delimiter character in
variable-length substrings is the first character of the
following substring;
4.
The method of signifying an undefined or null substring
within a fixed-length substring array is not explicitly
defined by this convention (note that there is no ambiguity
if the variable-length format is used). In most cases it is
recommended that a completely blank substring or other
adopted convention (e.g. 'INDEF') be used for
this purpose although general readers are not expected to
recognize these as undefined strings. In cases where it is
necessary to make a distinction between a blank, or other,
substring and an undefined substring use of variable-length
substrings is recommended;
5.
Undefined or null variable-length substrings are
designated by a zero-length substring, i.e., by a delimiter
character (or an ASCII NUL if it is the last substring in
the table field) in the first position of the substring. An
ASCII NUL in the first character of the table field
indicates that the field contains no defined variable-length
substrings;
6.
The "Multidimensional Array'' convention described in
Appendix .4
of this paper provides a syntax using the TDIMn keyword for describing multidimensional arrays
of any datatype which can also be used to represent arrays
of fixed-length substrings. For a one dimensional array of
substrings (a two dimensional array of characters) the
"Substring Array'' convention is preferred over the
"Multidimensional Array'' convention. Multidimensional
arrays of (fixed length) strings require the use of the
"Multidimensional Array'' convention;
7.
This substring convention may be used in conjunction
with the "Variable Length Array'' facility described in
Appendix .3
of this paper. In this case, the two possible full forms for
the value of the TFORM keyword are
TFORMn = 'rPA( ):SSTRw/nnn'
and
TFORMn = 'rPA( ):SSTRw'
for the variable and fixed cases, respectively.
This convention is optional and will not preclude other
conventions. This convention is not part of the binary table
definition.
Appendix C: Implementation on
physical media
(This Appendix is not part of the NOST FITS
Standard, but is included as a guide to recommended
practices.)
The arrangement of digital bits and other physical
properties of any medium should be in conformance with the
relevant national and/or international standard for that
medium.
For fixed block length sequential media where the
physical block size cannot be equal to or an integral multiple
of the standard FITS logical record length, a logical
record of fewer than 23040 bits (2880 8-bit bytes) immediately
following the end of the primary
header, data, or an extension should be
treated as an end-of-file. Otherwise, individual FITS
files should be terminated by a delimiter appropriate to the
medium, analogous to the tape end-of-file mark. If more than
one FITS file appears on a physical structure, the
appropriate end-of-file indicator should immediately precede
the start of the primary headers of all files after the first.
Storage of a single FITS
file on more than one unlabeled tape or on multiple units of
any other medium is not universally supported in
FITS. One possible way to handle multivolume
unlabeled tape was suggested in Wells et al. (1981).
A convention for logically grouping on-line FITS HDUs
that may physically be located in different sites has been
proposed in (Jennings et al. 1997).
Appendix D: Suggested time scale
specification
[Not part of formal DATExxxx agreement]
1.
Use of the keyword TIMESYS is suggested as an
implementation of the time scale specification. It sets the
principal time system for time-related keywords and data in
the HDU (i.e., it does not preclude the addition of keywords
or data columns that provide information for transformations
to other time scales, such as sidereal times or barycenter
corrections). Each HDU shall contain not more than one
TIMESYS keyword. Initially, officially allowed values are:
UTC
Coordinated Universal Time; defined since 1972.
UT
Universal Time, equal to Greenwich Mean Time (GMT)
since 1925; the UTC equivalent before 1972; see:
Explanatory Supplement, p. 76.
TAI
International Atomic Time; "UTC without the leap
seconds''; 31 s ahead of UTC on 1997-07-01.
AT
International Atomic Time; deprecated synonym of TAI.
ET
Ephemeris Time, the predecessor of TT; valid until
1984.
TT
Terrestrial Time, the IAU standard time scale since
1984; continuous with ET and synchronous with (but 32.184
s ahead of) TAI.
TDT
Terrestrial Dynamical Time; = TT.
TDB
Barycentric Dynamical Time.
TCG
Geocentric Coordinate Time; runs ahead of TT since
1977-01-01 at a rate of approximately 22 ms/year.
TCB
Barycentric Coordinate Time; runs ahead of TDB since
1977-01-01 at a rate of approximately 0.5 s/year.
For reference, see: Explanatory Supplement to the
Astronomical Almanac, P. K. Seidelmann, ed., University
Science Books, 1992, ISBN 0-935702-68-7, or
http://tycho.usno.navy.mil/systime.html
Use of Global Positioning Satellite (GPS) time (19 s
behind TAI) is deprecated.
2.
By default, times will be deemed to be as measured at
the detector (or in practical cases, at the observatory) for
times that run synchronously with TAI (i.e., TAI, UTC, and
TT). In the case of coordinate times (such as TCG and TCB)
and TDB which are tied to an unambiguous coordinate origin,
the default meaning of time values will be: time as if the
observation had taken place at the origin of the coordinate
time system. These defaults follow common practice; a future
convention on time scale issues in FITS files may
allow other combinations but shall preserve this default
behavior. The rationale is that raw observational data are
most likely to be tagged by a clock that is synchronized
with TAI, while a transformation to coordinate times or TDB
is usually accompanied by a spatial transformation, as well.
This implies that path length differences have been
corrected for. Note that the difference TDB - UTC, in that
case, is approximately sinusoidal, with period one year and
amplitude up to 500 s, depending on source position. Also,
note that when the location is not unambiguous (such as in
the case of an interferometer) precise specification of the
location is strongly encouraged in, for instance, geocentric
Cartesian coordinates.
3.
Note that TT is the IAU preferred standard. It may be
considered equivalent to TDT and ET, though ET should not be
used for data taken after 1984. For reference, see:
Explanatory Supplement, pp. 40-48.
4.
If the TIMESYS keyword is absent or has an unrecognized
value, the value UTC will be assumed for dates since 1972,
and UT for pre-1972 data.
5.
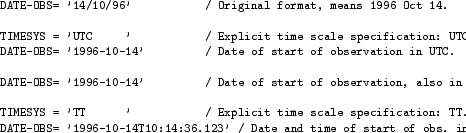
Examples. The three legal representations of the date of
October 14, 1996, might be written as shown in Table .1.
Table D.1: Three legal
representations of the date October 14, 1996.
6.
The convention suggested in this Appendix is part of the
mission-specific FITS conventions adopted for, and
used in, the RXTE archive, building on existing High Energy
Astrophysics FITS conventions. See:
The VLBA project has adopted a convention where the
keyword TIMSYS, rather than TIMESYS, is used, currently
allowing the values UTC and IAT. See p. 9 and
p. 16 of:
(This Appendix is not part of the
NOST FITS Standard but is included for informational
purposes only.)
Note: in this discussion, the term
the FITS papers refers to Wells et al. (1981),
Greisen & Harten (1981),
Grosbøl et al. (1988),
Harten et al. (1988),
Ponz et al. (1994),
and Cotton et al. (1995)
collectively; the term Floating Point Agreement (FPA)
refers to Wells & Grosbøl (1990);
the termBlocking Agreement
refers to Grosbøl & Wells (1994);
and the term DATExxxx Agreement refers to the
redefinition of the value format for date keywords approved by
the IAUFWG in 1997.
- This precise definition is
not used in the original FITS papers.
ASCII text
- This permissible subset of
the ASCII character set, used in many contexts, is not
precisely defined in the FITS papers.
Basic FITS
- This definition includes the
possibility of floating point data arrays, while the
terminology in the FITS papers refers to
FITS as described in Wells et al. (1981),
where only integer arrays were possible.
Conforming Extension
- This terminology is not used in theFITS papers.
Deprecate
- The concept of deprecation does not appear in the FITS
papers.
FITS structure
- This terminology is not used
in the FITS papers in the precise way that it is
in this standard.
Fraction
- This terminology and the
distinction between fraction and
mantissa do not appear in
the Floating Point Agreement.
Header and Data Unit
- This terminology is not used in the FITS
papers.
Indexed keyword
- This terminology is not used
in the original FITS papers.
Physical value
- This precise definition is
not used in the original FITS papers.
Reference point
- This term replaces the reference pixel of
theFITS papers. The new
terminology is consistent with the fact that the array
need not represent a digital image and that the reference
point (or pixel) need not lie within the array.
Repeat count
- This terminology is not used in the FITS
papers.
Reserved keyword
- The FITS papers
describe optional keywords but do not say explicitly that
they are reserved.
Standard Extension
- This precise definition is new. The term
standard extension is used in some contexts in
the FITS papers to refer to what this standard
defines as a standard extension and in others to
refer to what this standard defines
asconforming extension.
2.
Section 4.3.2.
Primary data array Fill format -
This specification is new. The
FITS papers and the FPA do not precisely specify
the format of data fill for the
primary data array.
3.
Section 4.4.1.1. Identity (of conforming
extensions) The FITS papers specify that
creators of new extension types should check with the FITS
standards committee. This standard identifies the committee
specifically, introduces the role of the FITS
Support Office as its agent, and mandates registration.
4.
Section 4.6.
Physical blocking This material is based entirely on
the Blocking Agreement. Material in
the early FITS papers [1,4] specifying the
expression of FITS on specific physical media is
not part of this standard.
5.
Section 4.6.1.
Bitstream devices The Blocking Agreement specifies that
this rule applies to FITS files written to logical
file systems. This standard applies the rule to all
bitstream devices, not only logical file systems.
6.
Section 4.6.2.1. Fixed block The Blocking
Agreement specifies that this rule applies to FITS
files written to optical disks, (accessed as a sequential
set of records), QIC format 1/4-inch cartridge tapes and
Local Area networks. This standard extends the rule to other
fixed block length sequential media.
7.
Section 4.6.2.2. Variable block The Blocking
Agreement specifies that this rule applies to FITS
files written to 1/2-inch 9 track tapes, DDS/DAT 4 mm
cartridge tapes and 8 mm cartridge tape (Exabyte). This
standard extends the rule to all variable block length
sequential media and eliminates references to specific
products.
8.
Section 5.1.2.1. Keyword (as header component)
The specification of permissible keyword characters is
new. The FITS papers do not precisely define the
permissible characters for keywords.
9.
Section 5.1.2.2. Value indicator (bytes 9-10)
The FITS papers do not specifically address the
permissibility of null values. This standard states
explicitly that they are permitted.
10.
Section 5.1.2.3. Value/comment (bytes 11-80) In
the FITS papers, the slash between the value and
comment is optional. This standard requires the slash,
consistent with the prescription of FORTRAN-77 list-directed
input.
11.
Section 5.2.
Value, including its subsections The FITS
papers specify that the value field is to be written
following the rules of ANSI FORTRAN-77 list-directed
input, with some restrictions. This standard explicitly
describes the format of the value field. The FITS
papers permit the value field to contain an array of values.
This standard specifies that there shall be only one value
in the value field. The FITS papers require the
fixed format for the most essential parameters. This
standard identifies those parameters with the values of the
mandatory keywords.
12.
Section 5.2.1.
Character string The standard explicitly describes how
single quotes are to be coded into keyword values, a rule
only implied by the FORTRAN-77 list-directed read
requirements of the FITS papers.
The standard states that in general, character-valued
keywords can have lengths up to the maximum 68 character
length.
13.
Section 5.2.4.
Real floating point number The standard explicitly notes
that the full precision of 64-bit values cannot be expressed
as a single value using the fixed
format.
14.
Section 5.2.5.
Complex integer number The standard does not support the
fixed format for complex integers defined in the
FITS papers but is consistent with FORTRAN-77
list-directed read as required in the
FITS papers for free format. Because the fixed
format of the FITS papers did not conform to the
rules for FORTRAN-77 list-directed I/O, consistency with
both was impossible. There are no known FITS files
that use the fixed format for complex integers that was
defined in the FITS papers.
15.
Section 5.2.6.
Complex floating point number The standard does not
support the fixed format for complex floating point numbers
defined in the FITS papers
but is consistent with FORTRAN-77 list-directed read as required in the FITS papers
for free format. Because the fixed format of the
FITS papers did not conform to the rules for
FORTRAN-77 list-directed I/O, consistency with both was
impossible. There are no known FITS files that use
the fixed format for complex floating point numbers that was
defined in the FITS papers.
16.
Section 5.3.
Units The FITS papers recommend the use of SI
units and identify certain other
units standard in astronomy. This standard codifies the
recommendation and makes it more specific by referring to
the IAU Style Manual (McNally 1988),
while explicitly recommending degrees for angular measure
and requiring degrees for celestial coordinates.
17.
Section 5.4.1.1. Principal (mandatory keywords)
(a)
SIMPLE keyword - The explicit prohibition against the
appearance of the SIMPLE keyword in extensions does not
appear in the FITS papers.
(b)
NAXIS keyword - The requirement
that the NAXIS keyword may not be
negative is not explicitly specified in the FITS
papers.
(c)
NAXISn keyword - The requirement that the NAXISn
keyword may not be negative is not
explicitly specified in the FITS papers.
18.
Section 5.4.1.2. Conforming extensions
(a)
- The requirement that may not be negative is not explicitly specified in the
FITS papers.
(b)
XTENSION keyword - That this keyword may not appear in the primary header
is only implied by the FITS papers; the
prohibition is explicit in this standard. The
FITS papers name a FITS standards
committee as the keeper of the list of accepted
extension type names. This standard
specifically identifies the committee and introduces the
role of the FITS Support Office as its agent.
19.
Section 5.4.2.
Other reserved keywords That the
optional keywords defined in the FITS papers are to
be reserved for both the primary HDUs and all extensions
with the meanings and usage defined in those papers, as in
the standard, is not explicitly stated in all of them,
although some keywords are explicitly reserved in the papers
describing the image and binary table extensions.
20.
Section 5.4.2.1. Keywords describing the history or
physical construction of the HDU
(a)
DATE keyword - The notation for four-digit year number
is YYYY rather than the CCYY of the "DATExxxx Agreement''.
The recommendation for use of Universal Time in the
superseded format with a two-digit year is not in the
FITS papers.
(b)
BLOCKED keyword - The FITS papers require the BLOCKED keyword to appear in the
first record of the primary header
even though it cannot when the value of NAXIS exceeds the values described in the text.
They do not address this contradiction. This standard
deprecates the BLOCKED keyword.
21.
Section 5.4.2.2. Keywords describing observations
(a)
DATE-OBS keyword - The recommendation for use of Universal Time in the superseded format with a
two-digit year is not in the FITS papers.
(b)
EQUINOX and EPOCH keywords - This standard replaces the
EPOCH keyword with the more appropriately named EQUINOX
keyword and deprecates the EPOCH
name.
22.
Section 5.4.2.4. Commentary keywords Keyword
field is blank - Wells et al. (1981)
contains the text "BLANK'' to represent a blank keyword
field. The standard clarifies the intention.
23.
Section 5.4.2.5. Array keywords
(a)
BUNIT keyword - The FITS papers recommend the
use of SI units, degrees as the
appropriate unit for angles, and
identify other units standard in
astronomy. This standard specifically applies the
recommendations of Sect. 5.3
to the BUNIT keyword.
(b)
CTYPEn, CRVALn, CDELTn, and CROTAn keywords - This
standard extends the recommendations on units to coordinate axes, explicitly
requiring decimal degrees for coordinates.
(c)
CRPIXn keywords - This standard explicitly notes the
ambiguity in the location of the
index number relative to an image pixel.
(d)
CDELTn keywords - The definition in the standard
differs from that in the FITS papers in that it
provides for the case where the
spacing between index points varies over the grid. For the
case of constant spacing, it is identical to the
specification in the FITS papers.
(e)
DATAMAX and DATAMIN keywords - The standard clarifies
that the value refers to the physical value represented by the array, after
any scaling, not the array value before scaling. The standard also
notes that special values are not
to be considered when determining the values of DATAMAX
and DATAMIN, an issue not specifically addressed by the
FITS papers or the FPA.
24.
Section 7.
Random groups structure The
standard deprecates the Random Groups
structure.
25.
Section 7.1.2.
Reserved keywords (random groups) That the optional keywords defined in the
FITS papers are to be reserved with the meanings
and usage defined in those papers, as in the standard, is
not explicitly stated in them.
26.
Section 7.1.2.2. PSCALn keywords - The default
value is explicitly specified in the standard, whereas in
the FITS papers it is assumed by analogy with the BSCALE
keyword.
27.
Section 7.1.2.3. PZEROn keywords - The default
value is explicitly specified in the standard, whereas in
the FITS papers it is assumed by analogy with the BZERO
keyword.
28.
Section 8.1.
ASCII table extension The name ASCII table is
given to the "tables'' extension
discussed in the FITS papers
to distinguish it from the binary table extension.
NAXIS1 keyword - The
requirement that the NAXIS1 keyword may not be negative in
an ASCII table header is not explicitly specified in the FITS papers.
(b)
NAXIS2 keyword - The requirement that the NAXIS2
keyword may not be negative in an ASCII table header is
not explicitly specified in the
FITS papers.
(c)
TFIELDS keyword - The requirement that the TFIELDS
keyword may not be negative is not explicitly specified
in the FITS papers.
(d)
TFORMn keyword - The requirement that format codes
must be specified in upper case is implied but not
explicitly specified in the
FITS papers.
30.
Section 8.1.2.
Other reserved keywords (ASCII table) That the optional keywords defined in the
FITS papers are to be reserved with the meanings
and usage defined in those papers, as in the standard, is
not explicitly stated in them.
(a)
TUNITn keywords - The FITS papers do not explicitly recommend the use
of any particular units for this
keyword, although the reference to the BUNIT keyword may
be considered an implicit extension of the recommendation for that keyword.
This standard makes the recommendation more specific for
the TUNITn keyword by requiring conformance to the
prescriptions in Sect. 5.3.
(b)
TSCALn keywords - The prohibition against use in
A-format fields is stronger than the statement in the
FITS papers that the keyword "is not relevant''.
(c)
TZEROn keywords - The prohibition against use in
A-format fields is stronger than the statement in the
FITS papers that the keyword "is not relevant''.
31.
Section 8.3.2.
Other reserved keywords (Binary Table) The EXTNAME,
EXTVER, EXTLEVEL, AUTHOR, and REFERENC keywords explicitly
reserved for binary tables in the defining paper are
reserved in the standard under the general prescription of
Sect. 5.4.2.
(a)
TUNITn keywords - The FITS papers do not explicitly recommend the use
of any particular units for this
keyword. This standard makes the recommendation more
specific for the TUNITn keyword by requiring conformance
to the prescriptions of Sect. 5.3.
(b)
TDISPn keywords - The version
of the BINTABLE paper upon which the FITS
committees voted stated incorrectly that the values used
to display bit and byte arrays should be considered
signed. This standard follows the text in the
published BINTABLE paper, which specifies that these
values should be unsigned. The BINTABLE paper
does not specify how a TDISPn value for a field of
type P is interpreted; this standard explicitly
mandates no interpretation but allows conventions to
provide interpretations. The requirement that format codes
must be specified in upper case is implied but not
explicitly specified in the BINTABLE paper.
(c)
THEAP keywords - The FITS papers state only that the keyword is
reserved for use in the convention described in Appendix
.3.
This standard makes the more specific statement that this
keyword is used to provide the separation, in bytes,
between the start of the main data table and the start of
a supplemental data area called the
heap and identifies the default value.
(d)
TDIMn keywords - The FITS papers state only that the keyword is reserved for
use in the convention described in Appendix .4.
This standard makes the more specific statement that the
contents of the value field contain a character string
describing how to interpret the contents of a field as a
multidimensional array.
32.
Section 8.3.4.
Data display The BINTABLE paper suggests that the format
for display suggested by the TDISPn should be understood as
a Fortran-90 format or, where Fortran-90 is unavailable, a
FORTRAN-77 format. This standard explicitly describes the
formats. The statement in the standard concerning
differences between E and D format codes, which notes that
the latter implies greater precision in the internal datum,
does not appear in the BINTABLE paper.
33.
Section 9.
Restrictions on changes The FITS papers do not
provide for the concept of deprecation.
34.
Appendix .6
implementation on physical media Material in the
FITS papers specifying the expression of
FITS on specific physical media is not part of this
standard; what is provided in the Appendix is purely as a
guide to recommended practices.
Appendix F: Summary of keywords
(This Appendix is not part of the NOST FITS
Standard, but is included for convenient reference). Tables
F.1, F.2, and F.3 list the mandatory and reserved
FITS keywords.
Table F.1: Mandatory FITS
keywords for the structures described in this
document.
Principal
Conforming
ASCII Table
Image
Binary Table
Random Groups
HDU
Extension
Extension
Extension
Extension
Records
SIMPLE
XTENSION
XTENSION1
XTENSION2
XTENSION3
SIMPLE
BITPIX
BITPIX
BITPIX = 8
BITPIX
BITPIX = 8
BITPIX
NAXIS
NAXIS
NAXIS = 2
NAXIS
NAXIS = 2
NAXIS
NAXISn4
NAXISn4
NAXIS1
NAXISn4
NAXIS1
NAXIS1 = 0
EXTEND5
PCOUNT
NAXIS2
PCOUNT = 0
NAXIS2
NAXISn4
END
GCOUNT
PCOUNT = 0
GCOUNT = 1
PCOUNT
GROUPS = T
END
GCOUNT = 1
END
GCOUNT = 1
PCOUNT
TFIELDS
TFIELDS
GCOUNT
TBCOLn6
TFORMn6
END
TFORMn6
END
END
1XTENSION= 'TABLE' for the ASCII
table extension. 2XTENSION= 'IMAGE' for the image extension. 3XTENSION=
'BINTABLE' for the binary table extension. 4
Runs from 1 through the value of NAXIS. 5
Required only if extensions are present. 6 Runs
from 1 through the value of TFIELDS.
Table F.2: Reserved FITS
keywords for the structures described in this
document.
All
Array1
Conforming
ASCII Table
Binary Table
Random Groups
HDUs
HDUs
Extension
Extension
Extension
Records
DATE
BSCALE
EXTNAME
TSCALn
TSCALn
PTYPEn
ORIGIN
BZERO
EXTVER
TZEROn
TZEROn
PSCALn
BLOCKED2
BUNIT
EXTLEVEL
TNULLn
TNULLn
PZEROn
AUTHOR
BLANK
TTYPEn
TTYPEn
REFERENC
CTYPEn
TUNITn
TUNITn
COMMENT
CRPIXn
TDISPn
HISTORY
CROTAn
TDIMn
CRVALn
THEAP
DATE-OBS
CDELTn
TELESCOP
DATAMAX
INSTRUME
DATAMIN
OBSERVER
OBJECT
EQUINOX
EPOCH2
1 Primary HDU, image extension, user-defined
HDUs with same array structure. 2 Deprecated.
Table F.3: General reserved
FITS keywords described in this document.
Production
Bibliographic
Commentary
Observation
DATE
AUTHOR
COMMENT
DATE-OBS
ORIGIN
REFERENC
HISTORY
TELESCOP
BLOCKED1
INSTRUME
OBSERVER
OBJECT
EQUINOX
EPOCH1
1 Deprecated.
Appendix G: ASCII text
(This Appendix is not part of the NOST FITS
standard; the material in it is based on the ANSI standard for
ASCII (ANSI 1977)
and is included here for informational purposes.)
In Table G.1, the first column is the decimal and the second column the hexadecimal
value for the character in the third column. The characters
hexadecimal 20 to 7E (decimal 32 to 126) constitute the subset
referred to in this document as ASCII text.
Table G.1: ASCII character
set.
ASCII Control
ASCII Text
dec
hex
char
dec
hex
char
dec
hex
char
dec
hex
char
0
00
NUL
32
20
SP
64
40
@
96
60
`
1
01
SOH
33
21
!
65
41
A
97
61
a
2
02
STX
34
22
"
66
42
B
98
62
b
3
03
ETX
35
23
#
67
43
C
99
63
c
4
04
EOT
36
24
$
68
44
D
100
64
d
5
05
ENQ
37
25
%
69
45
E
101
65
e
6
06
ACK
38
26
&
70
46
F
102
66
f
7
07
BEL
39
27
'
71
47
G
103
67
g
8
08
BS
40
28
(
72
48
H
104
68
h
9
09
HT
41
29
)
73
49
I
105
69
i
10
0A
LF
42
2A
*
74
4A
J
106
6A
j
11
0B
VT
43
2B
+
75
4B
K
107
6B
k
12
0C
FF
44
2C
,
76
4C
L
108
6C
l
13
0D
CR
45
2D
-
77
4D
M
109
6D
m
14
0E
SO
46
2E
.
78
4E
N
110
6E
n
15
0F
SI
47
2F
/
79
4F
O
111
6F
o
16
10
DLE
48
30
0
80
50
P
112
70
p
17
11
DC1
49
31
1
81
51
Q
113
71
q
18
12
DC2
50
32
2
82
52
R
114
72
r
19
13
DC3
51
33
3
83
53
S
115
73
s
20
14
DC4
52
34
4
84
54
T
116
74
t
21
15
NAK
53
35
5
85
55
U
117
75
u
22
16
SYN
54
36
6
86
56
V
118
76
v
23
17
ETB
55
37
7
87
57
W
119
77
w
24
18
CAN
56
38
8
88
58
X
120
78
x
25
19
EM
57
39
9
89
59
Y
121
79
y
26
1A
SUB
58
3A
:
90
5A
Z
122
7A
z
27
1B
ESC
59
3B
;
91
5B
[
123
7B
{
28
1C
FS
60
3C
<
92
5C
\
124
7C
|
29
1D
GS
61
3D
=
93
5D
]
125
7D
}
30
1E
RS
62
3E
>
94
5E
^
126
7E
~
31
1F
US
63
3F
?
95
5F
_
127
7F
DEL1
1 Not ASCII Text
Appendix H: IEEE floating point
formats
(The material in this Appendix is
not part of this standard; it is adapted from the IEEE-754
floating point standard (IEEE 1985)
and provided for informational purposes. It is not intended to
be a comprehensive description of the IEEE formats; readers
should refer to the IEEE standard.) FITS recognizes
all IEEE basic formats, including the special values.
Numbers in the single and double formats are
composed of the following three fields:
1.
1-bit sign s
2.
Biased exponent
3.
Fraction
The range of the unbiased exponent E
shall include every integer between two values and , inclusive, and also two other reserved values to encode and denormalized numbers, and +1 to encode and NaNs. The foregoing parameters are
given in Table .6.
Each nonzero numerical value has just one encoding. The fields
are interpreted as follows:
Table .7
shows the types of IEEE floating point value, whether regular
or special, corresponding to all double and single precision
hexadecimal byte patterns.
Table H.2: IEEE floating point
formats.
IEEE value
Double Precision
Single Precision
+0
0000000000000000
00000000
denormalized
0000000000000001
00000001
to
to
000FFFFFFFFFFFFF
007FFFFF
positive underflow
0010000000000000
00800000
positive numbers
0010000000000001
00800001
to
to
7FEFFFFFFFFFFFFE
7F7FFFFE
positive overflow
7FEFFFFFFFFFFFFF
7F7FFFFF
7FF0000000000000
7F800000
NaN1
7FF0000000000001
7F800001
to
to
7FFFFFFFFFFFFFFF
7FFFFFFF
-0
8000000000000000
80000000
negative
8000000000000001
80000001
denormalized
to
to
800FFFFFFFFFFFFF
807FFFFF
negative underflow
8010000000000000
80800000
negative numbers
8010000000000001
80800001
to
to
FFEFFFFFFFFFFFFE
FF7FFFFE
negative overflow
FFEFFFFFFFFFFFFF
FF7FFFFF
FFF0000000000000
FF800000
NaN1
FFF0000000000001
FF800001
to
to
FFFFFFFFFFFFFFFF
FFFFFFFF
1 Certain values may be designated as
quiet NaN (no diagnostic when used) or
signaling (produces diagnostic when used) by
particular implementations.
Appendix I: Reserved extension
type names
(This Appendix is not part of the NOST
FITS Standard, but is included
for informational purposes. It describes the extension type
names registered as of the date this standard was issued.)
Tables I.1 and I.2 give the currently reserved
FITSextension type names. A current list is available from
the FITS Support Office at

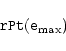
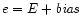
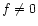 , then v is NaN regardless of s
, then v is NaN regardless of s
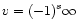
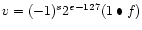
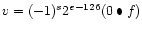 (denormalized numbers)
(denormalized numbers)
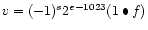
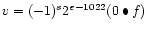 (denormalized numbers)
(denormalized numbers)